
课程简介
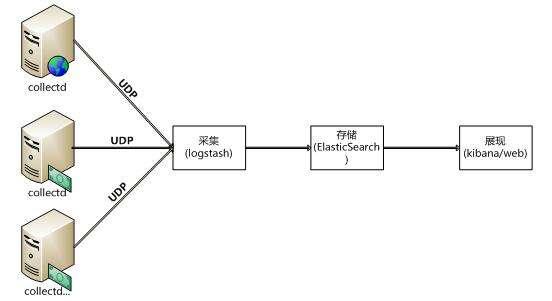
系统运维和开发人员在日常工作通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。单台机器的日志使用grep、awk等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上,使用依次登录每台机器的传统方法查阅日志会显得繁琐和效率低下。不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
课程收益
1、掌握项目成本的构成以及项目成本管理框架;
2、掌握项目成本的规划;
3、掌握项目成本的估算和预算;
4掌握项目成本控制与结算。
受众人群
大数据开发人员、大数据运维人员、运维工程师、大数据科学家、算法研究者及系统架构师等
课程周期
1天(6H)
课程大纲
课程主题 | 课程内容 |
Part 1 入库速度和查询速度权衡 | 1.如何提高入库速度 2.如何提高查询速度 3.如何在入库速度和查询速度之间获得平衡(重要) |
Part 2 如何让ES查询更方便 | 1.支持SQL查询 a.ElasticSearch-SQL b.Spark-SQL 2.开发一个QueryEngine,支持管理和查询所有ES集群 |
Part 3 ES查询的精度问题 | 1.一定存在误差的场景 2.可能存在误差的场景 |
Part 4 如何加快ES故障恢复 | 1.ES recovery原理分析 2.加快Recovery的一些常见参数 |
Part 5 保证集群的高可用 | 1.合理的参数配置 2.合理的监控报警 3.双写 |
Part 6 集群规划 | 1.节点类型 2.集群内部组划分(Tag) 3.多集群 |
Part 7 数据归档和恢复 | 1.冷热分离 2.归档 3.转储(如HDFS) 4.定时清理 |
Part 8 ES周边 | 1.常见Pipline(技术组合) a.Logstach+ES+Kibana b.Logstach/Flume+Kafka+Storm/Spark+ES+Kibana c.优缺点和适用场景 2.和大数据的整合ElasticSearch Hadoop介绍 3.StreamingPro介绍 4.Flume/Nginx+Kafka+SparkStreaming+ES+Kibana/Spark SQL分析 |
Part 9 ES和其他大数据解决方案的区别 | 1.Apache Kylin 2.Apache Carbondata 3.Spark SQL+Parquet 4.Apache Druid 5.Apache Impala |
Part 10 ES源码导读(Optional) | 1.ES内部Rest/RPC接口调用体系 2.ES如何和Lucene进行衔接 3.如何在代码中查看一些undocument的参数 |




 京ICP备2022035414号-1
京ICP备2022035414号-1
