

课程简介
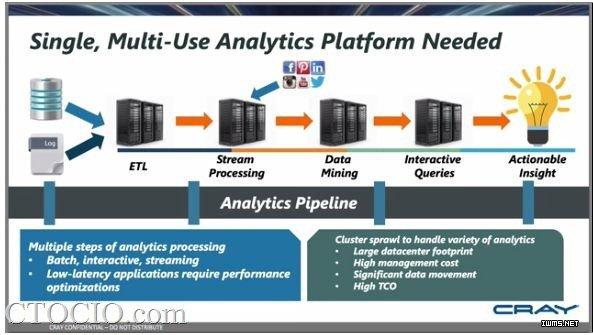
得益于互联网信息技术的快速发展,大数据已经成为当今技术革新的一大发展趋势。从大数据的整体架构上看来,大数据的核心层可以归结为:数据采集、数据存储与分析、数据共享、数据应用。
课程收益
1.了解开源大数据常用生态组件;
2.掌握大数据技术在现实场景中的应用。
受众人群
大数据爱好者、软件开发工程师、数据库开发人员、数据分析师、网络后台开发人员、运维人员、项目经理和对大数据内容感兴趣并想提升的人员。
课程周期
3天(18H)
课程大纲
课程主题 | 课程内容 |
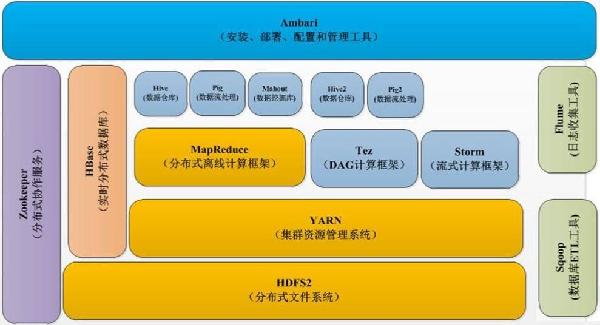
开源大数据常用生态组件和华为FI介绍 | l 主要内容 大数据的整体技术架构 Ø 开源大数据技术架构 Ø 分布式存储—HDFS Ø 离线计算框架介绍 —Mapreduce、Hive、Tez、Presto、Kylin Ø 数据采集工具介绍 —Sqoop和Flume Ø 实时查询框架介绍 —NoSQL、Hbase Ø 实时计算框架介绍 —Kafka、Strom、Spark Streaming Ø 内存计算框架介绍 —Spark、SparkSQL、SparkMllib、SparkR Ø 前沿大数据技术介绍 —Flink、Drill、Druid、KUDU等 Ø 海量日志快速检索架构 —ELK(Elasticsearch、Logstash、Kibana)等 Ø 华为大数据平台的介绍 |
数据分析技术介绍和比较(SQL on Hadoop) | l 主要内容 Ø M-OLAP分析应用场景介绍 Ø Kylin实现M-OALP介绍 Ø R-OLAP应用分析场景介绍 Ø SparkSQL应用场景介绍 Ø Impala应用场景介绍 Ø Presto应用场景介绍 Ø sparkSQL、Impala和Presto之间的比较 Ø Elasticsearch应用场景介绍 Ø ELK应用案例介绍和分享 Ø Elk技术介绍 Ø Elk的应用场景介绍 Ø Elk与Impala的比较 |
数据仓库设计架构 | l 主要内容 Ø 数据仓库典型架构介绍 —ODS层 —DW层 —DM层 Ø 数据安全控制 Ø ETL任务调度 Ø 元数据管理 |
数据湖设计架构 | l 主要内容 Ø 数据湖概念介绍 Ø 数据湖分区介绍 —着落区 —处理区 —表达去 —探索区 Ø 数据湖实现的技术介绍 Ø 数据湖与数据仓库之间的关系 |
企业级大数据平台的数据架构 | l 主要内容 Ø 数据接入大数据平台 —离线数据接入 —实时的数据接入 Ø 数据处理过程 —数据的ETL —数据分层(ODS、DW和DM等) —数据建模 —数据校验 Ø 数据应用 —数据离线应用 —数据实时应用 —数据实验室 Ø 大数据平台与MPP的应用定位 Ø 大数据平台与MPP之间的数据应用 |
分布式存储HDFS | l 主要内容 Ø HDFS架构介绍 Ø HDFS原理介绍 Ø NameNode功能详解 Ø DataNode功能详 Ø HDFS HA功能详解 Ø HSFD的fsimage和editslog详解 Ø HDFS的block详解 Ø HDFS的block的备份策略 Ø Hadoop的机架感知配置 Ø HDFS的权限详解 |
分布式计算MapReduce | l 主要内容 Ø Mapreduce原理 Ø MapReduce流程 Ø 剖析一个MapReduce程序 Ø Mapper和Reducer抽象类详解 Ø Combiner详解 Ø Partitioner详解 Ø 任务调度 Ø 默认的任务调度 Ø 公平任务调度 Ø 能力任务调度 |
分布式资源管理Yarn | l 主要内容 Ø Yarn的原理和架构 Ø Yarn资源调度策略 Ø CPU、内存和IO三种资源调度优化 Ø Yarn资源调度Fair和Capacity详解 Ø Yarn动态资源的设置 Ø 动态分配特定节点给每个应用(MR、Strom、Spark、Hbase等) 基于Yarn的资源控制详解 |
HIVE数据仓库集群的多维分析建模应用实践 | l 主要内容 Ø 基于Hadoop的大型分布式数据仓库在行业中的数据仓库应用案例 Ø Hive数据仓库集群的平台体系结构、核心技术剖析 Ø Hive Server的工作原理、机制与应用 Ø Hive数据仓库集群的安装部署与配置优化 Ø Hive应用开发技巧 Ø Hive SQL剖析与应用实践 Ø Hive数据仓库表与表分区、表操作、数据导入导出 Ø Hive数据仓库报表设计 Ø Hive数据仓库表的文件格式介绍 Ø 基于Hive的数据分层实现 (ODS、DW、DWS/B、DM、ST) |
NoSQL和Hbase使用 | l 主要内容 Ø NoSQL介绍 Ø NoSQL应用场景 Ø Hbase的架构原理 Ø Hbase核心概念详解(HMaster、HRegionServer、Store、StoreFile、HFile、HLog和MetaStore) Ø Hbase自带的namesapce和Meta表详解 Ø HBase逻辑视图介绍 Ø HBase物理视图介绍 Ø HBase的RowKey设计原则 Ø HBase BloomFilter的介绍 Ø Hbase表的设计案例 Ø 手动设置Split和Compaction操作 Ø Pre-Split的介绍 Ø HBase Region的迁移优化 Ø HBase 的表结构优化 Ø HBase使用场景介绍 Ø HBase案例分析 |
Spark编程模型和解析 | l 主要内容 Ø Spark的编程模型 Ø Spark编程模型解析 Ø Partition实现机制 Ø RDD的特点、操作、依赖关系 Ø Transformation RDD详解 Ø Action RDD详解 Ø Spark的累加器详解 Ø Spark的广播变量详解 Ø Spark容错机制 — lineage和checkpoint详解 Ø Spark的运行方式 Ø Spark的Shuffle原理详解 — Sort-Based原理 — Hash-Based原理 Spark2.0的新特性 |
Spark SQL原理和实践 | l 主要内容 Ø Spark SQL原理 Ø Spark SQL的Catalyst优化器 Ø Spark SQL内核 Ø Spark SQL和Hive连接 Ø DataFrame和DataSet架构 Ø Fataframe、DataSet和Spark SQL的比较 Ø SparkSQL parquet格式实战 Ø Spark SQL的实例和编程 Ø Spark SQL的实例操作demo Ø park SQL的编程 |
Spark Streaming详解 | Ø Spark Streaming原理 Ø Spark Streaming的应用场景 Ø Windows 窗口操作 Ø DStream详解 Ø Spark SQL on Spark Streaming详解 Ø Structured Streaming介绍 |
Spark 数据挖掘基于 | Ø SparkMllib功能介绍 Ø 基于Spark Mllib数据挖掘的流程 Ø 基于Spark Mllib实现回归应用 Ø Graphx架构个原理 Ø Graphx图的构建要素 Ø Graphx图操作介绍 |
案例实战 | Ø 某大型商业银行企业级大数据平台案例分享 Ø 问答 |

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员




 京ICP备2022035414号-1
京ICP备2022035414号-1
